電子書籍ケーススタディ 5
| DTPからXMLへ |
イースト株式会社 下川 和男
前回、「PDFかXMLか」というテーマで、XMLとPDFの現状を説明したが、今回はその続編で、DTPファイルをXMLに変換する具体的な方法をご紹介する。
弊社が採用している方法は、いかにもソフトウェア会社らしい方法だが、今後、需要が急増するXML化作業の参考にしていただきたい。
はじめに官報ありき
弊社は、インターネットやWindowsに関連したソフトウェアを開発する会社だが、1999年12月に、妙な縁で、官報のXML化をお手伝いし、その延長で、ドキュメントのXML化作業を今でも毎月1万頁ほど行っている。
官報のXML化は、戦後すべての官報、全88万頁について、各頁のコピーを受領し、XMLファイルを納品する作業が当時の大蔵省から発注された。イーストは、落札業者数社から、合計12万頁のXML化作業を受注した。弊社が担当したのは、デジタル化済みのテキストファイルから、官報DTDに沿ったXMLタグ付きのデータを作成する部分である。
この作業は、大きく以下の工程で行った。
| 1.自動タグ付け ⇒ 2.手動タグ付け ⇒ 3.表や図の設定 ⇒ 4.最終確認 |
「タグは機械が処理するものなので、機械で付ける」、「膨大なドキュメントの処理は、コンピュータが行うべき」という考え方から、徹底的なシステム化を行った。
1.の自動タグ付けは、プレーンなテキストデータを読み、文字パターンの検索や前後の文章から、可能な限り、タグ付けを行うもので、官報の年代やジャンルに合わせた、多数の自動変換プログラムを作成した。
2.は自動変換が不可能なタグについて、アルバイトでも使えるようなシンプルな専用エディタを開発し、これを使って、人海戦術で行った。
3.は官報には決算書などの複雑な表が多数存在するので、その熟練工を養成し、図も含めて、別工程とした。
4.は文字校正は弊社の責任外だったので、レイアウトやタグについての校正を、当時、ベータ版が登場していた、Internet Explorer 5.5の縦書き表示機能と文字鏡URLフォントによる外字表示機能を使って、できるだけ平易な作業にして生産性を高めた。
3.で別工程などと簡単に書いたが、一般的な事務作業で、工程の変更や細分化は難しいが、これらのデジタル化作業のすべてを、vfolderという工程とコンテンツを管理するサーバを使って行い、成果をあげることができた。
DTPからXMLへ
官報のXML化を担当した理由は、JepaXにより印刷業界で多少、社名が知れていた為だが、官報XML化プロジェクトの受注により、その後も、書籍からXMLへの変換作業の依頼がきている。
日本では、DTPで作られた書籍は少ないが、技術系の出版社はDTPを多用しており、そのような出版社のDTPファイルをXMLに変換する仕事が多い。DTPと一言でいっても、Quark、PageMaker、In Design、Wordなど、アプリケーションソフトによって変換方法が異なる。問題集などは、Accessのデータで提供される場合もある。
これらのDTPファイルを、可能な限りコンピュータを使って変換している。
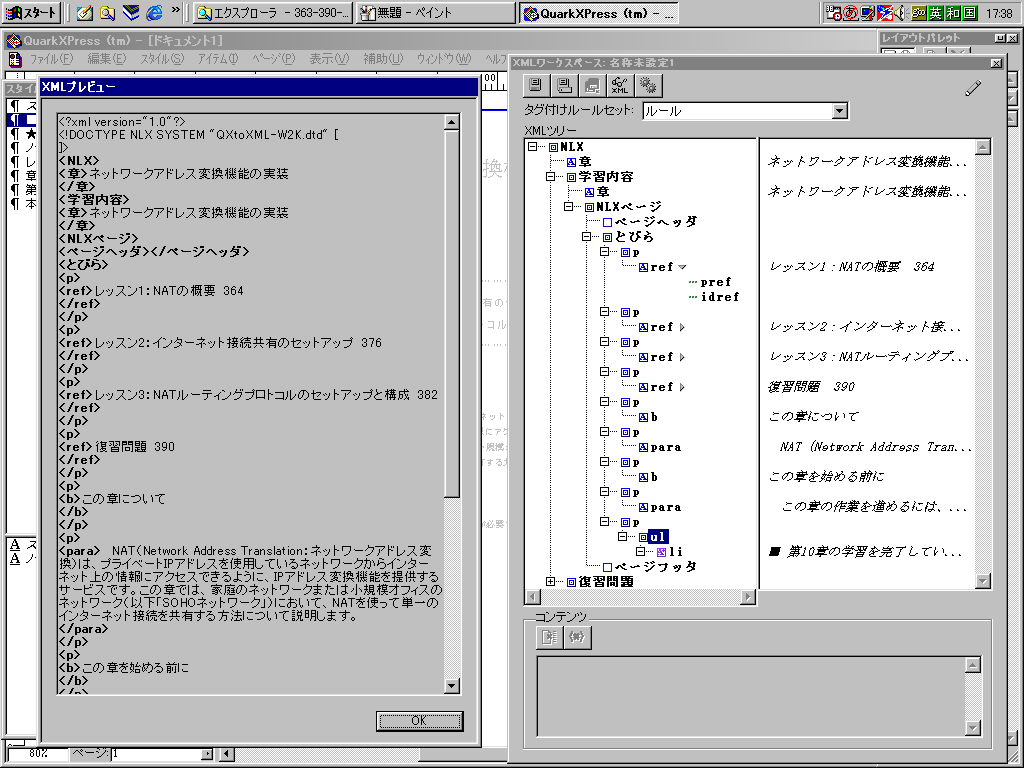
Quarkの場合は、図の通り、avenue.quarkを使ってXML変換を行っているが、「頁単位の変換で、操作が面倒」、「日本語タグに対応していない」などの問題が発生した。前者は、avenue.quarkが、書籍ではなく新聞や雑誌などの変換を想定しているので、今後のバージョンアップを待つしかない。後者は、XMLはUnicodeベースなので、日本語タグも難なく設定できるが、外国製のツールを使うときに問題となる。しかし、これも、英語タグを適当に決めて変換し、その後、テキスト・コンバータで一気に日本語タグへの変換を行っている。
WordやPageMakerの場合は、HTMLファーマットでの一括書出し機能使ってHTMLファイルを作成している。これをJavaScriptで変換プログラムを作成し、XMLに落としている。PerlやVisual BasicではなくJavaScriptを使う理由は、DOM(ドム)が扱えるからである。
DOM(Document Object Model)は、XMLドキュメントを操作するためのアプリケーション・インタフェースで、官報XML化プロジェクト以来、これを使って、XMLドキュメントの解析や生成を行っている。
avenue.Quarkの場合は、書籍の構造を、そのままXMLにしてくれるので、しっかり文書構造を決めて製作された書籍であれば、すぐにXML化できる。しかし、HTMLの場合は、「構造」と呼べるほどの情報が含まれていないので、書籍のレイアウト上の特徴や、特有の文字列などを手がかりにして、一冊、一冊、JavaScriptのプログラムを作成している。
一冊ごとにプログラムを作るなんて!と思われるかもしれないが、プログラマーが100人以上いる会社なので、お手の物である。何回か試行錯誤の後、プログラムが完成すれば、1000頁の書籍でも数秒で、XMLファイルが生成される。
この後、表や図の貼り込みや最終確認などの作業を行うが、目次作成はXSLで簡単に行えるし、索引作成には、事例その2「三省堂 e辞林」でご紹介した、LaBambaという全文インデックス生成ツールが応用できる。
Adobe In DesignからのXML変換は、いくつかのルートがあるので現在、弊社にとっての最短ルートを調査中である。Accessからの変換は、問題集程度であれば、CSVファイルをJavaScriptでXMLに変換している。
XMLからPDFへ
4月の東京国際ブックフェアでAdobe社がContent ServerとAcrobat eBook Readerという電子書籍の仕組みを発表した関係で、Adobe eBookの基本フォーマットである、PDF製作の依頼も増えている。
前出のQuark、PageMaker、WordなどのDTPソフトで作られた書籍の場合は、Acrobatを使って、数回のクリックでPDFファイルが作成できるが、事例その4「PDFかXMLか」でご紹介した通り、JepaXやHTMLからDTPソフトへの流し込みはちょっと厄介である。QuarkやIn Designには、入出力が可能なオリジナルのタグが用意されているので、JavaScriptを使って各フォーマットへの変換を行っている。
DTPソフトに流し込んだドキュメントは、手作業でページレイアウトの調整を行い、eBook化を行っている。この際、Acrobat eBook Readerの特徴である二頁表示を行うには、一頁を20行×40文字程度に抑える必要がある。
eBookを作る場合、外字のインライン化、画像の低解像度化、表紙画像の作成、コピーや印刷などの許諾範囲の設定を行い、DRM(デジタル著作権管理)処理を入れる。このファイルをAdobe Content Serverに対応したオンラインショップに登録すれば、電子書籍の販売がスタートできる。
| Kazuo Shimokawa [EAST Co., Ltd.] |